DomoAIの使い方や料金、無料でできることを解説!プロが忖度抜きでガチレビュー
ryo
HENSHIN Lab


画像生成AIの代表格として知られているのが「Stable Diffusion」です。日々、AI情報に敏感な方にはよく知られていても、一般の方にはまだまだ知られていないかもしれません。
ここでは、Stable Diffusionとは何か、どのようなことができるのかと言った機能をご紹介。WindowsやMacなどのOSに応じた導入方法、使い方の基礎や応用など幅広く解説しています。
これから画像生成AIについて知りたい、学びたいという方は、その導入としてStable Diffusionに触れてみてください。
お困りの方はTeam HENSHINまでご質問ください。

Stable Diffusionは、テキストから画像を生成できるAIツールです。誰でも無料で使用することが可能です。ユーザーが入力したテキストプロンプトに応じて、様々なスタイルやテーマの画像を生み出すことができます。
Stable Diffusionはオープンソースで開発されたAIのため、誰でも無料で使用することが可能です。深層学習と大規模な画像データベースを利用して、瞬時に高品質な画像生成を可能にしています。
Stable Diffusionの高度な画像生成能力により、クリエイティブな分野やビジネスの様々な場面で注目されています。
画像生成という高度な技術を持ち合わせたStable Diffusionですが、どのような仕組みで画像を生成しているのでしょうか。
ここでは、Stable Diffusionの仕組みについて解説します。
Stable Diffusionの画像生成プロセスは、初期のざっくりとした画像から始まり、徐々に細かいディテールを加えていく方法です。この方法では、AIがまず大まかなイメージを作り、次第にそのイメージを詳しく、くっきりとした画像に進化させます。
このプロセス中、AIは入力されたテキストの内容を理解し、その内容に合った画像を作り出します。つまり、AIはテキストの意味を把握し、それに基づいて画像を具体化することができるのです。
Stable Diffusionは先進的なニューラルネットワーク(AIにおける脳)のアーキテクチャが採用されています。
アーキテクチャとは、コンピューターシステム、ソフトウェア、またはAIなどの技術的な構造や設計のことで、どのようなアルゴリズムやデータ構造が使われるか、またそれらがどのように相互作用するかなどです。
このアーキテクチャは、テキストからの高品質な画像生成を可能にするために特別に設計されています。大量の画像とテキストデータを基にトレーニングされ、テキストプロンプトを解釈し、それに対応するビジュアルを生成する能力を持っています。
Stable Diffusionは生成する画像のリアリティや多様性を維持しながら、効率的に画像を生成するよう最適化されており、最新のディープラーニング技術を駆使しています。
Stable Diffusionと他の画像生成AIとの主な違いは、何といっても無料で使用できる点とパラメータによる細かい設定です。
Stable Diffusionはオープンソースで開発された画像生成AIのため、環境構築さえできれば誰でも無料で使用することが可能です。また、後述するモデルやLORAなども多くのユーザーによって公開されているのも強みです。
加えて、豊富なパラメータで細かで柔軟に設定できることも強みです。画像の幅や高さから、短時間でざっくり生成するのか時間をかけて品質重視で生成するのかなどの調整も可能です。
他の画像生成AIの多くは有料であり、設定の豊富さもStable Diffusionに劣る場合が多いです。そもそも、Stable DiffusionのAPIを利用して展開されているサービスも多いため、大本がこのStable Diffusionであることもあります。
それほど、画像生成AIの中でもStable Diffusionは大御所的な存在になってきているのです。
ここからはStable Diffusionの機能について解説していきます。まずはどのようなことができるのかを把握し、自身の画像生成に活かしましょう。
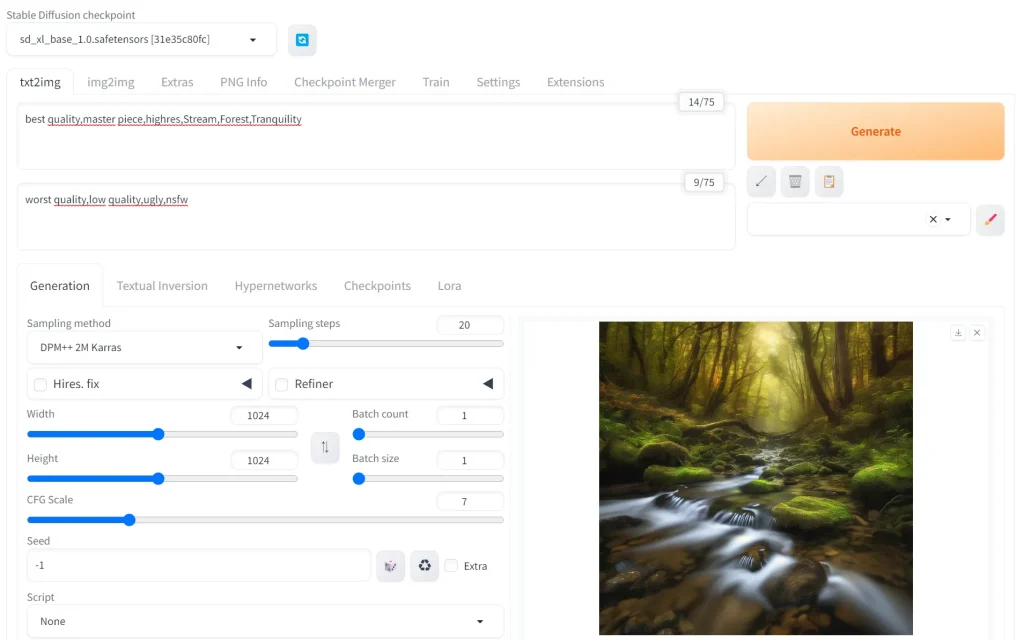
Stable Diffusionの「txt2img」では、ユーザーが入力したテキストプロンプトを基に、画像を生成します。
この過程では、AIがテキストの内容を解析し、その記述に合ったビジュアルを創出します
例えば、ユーザーが「夕日に照らされた静かな湖」というテキストを入力すると、Stable Diffusionはこの描写に基づいた画像を生成します。
テキストからの画像生成は非常に高度な機能で、抽象的なコンセプトや詳細な記述も理解することができます。
また、ユーザーが特定のアートスタイルや色彩を指定することも可能で、AIはこれらの要素を取り入れた画像を創造します。
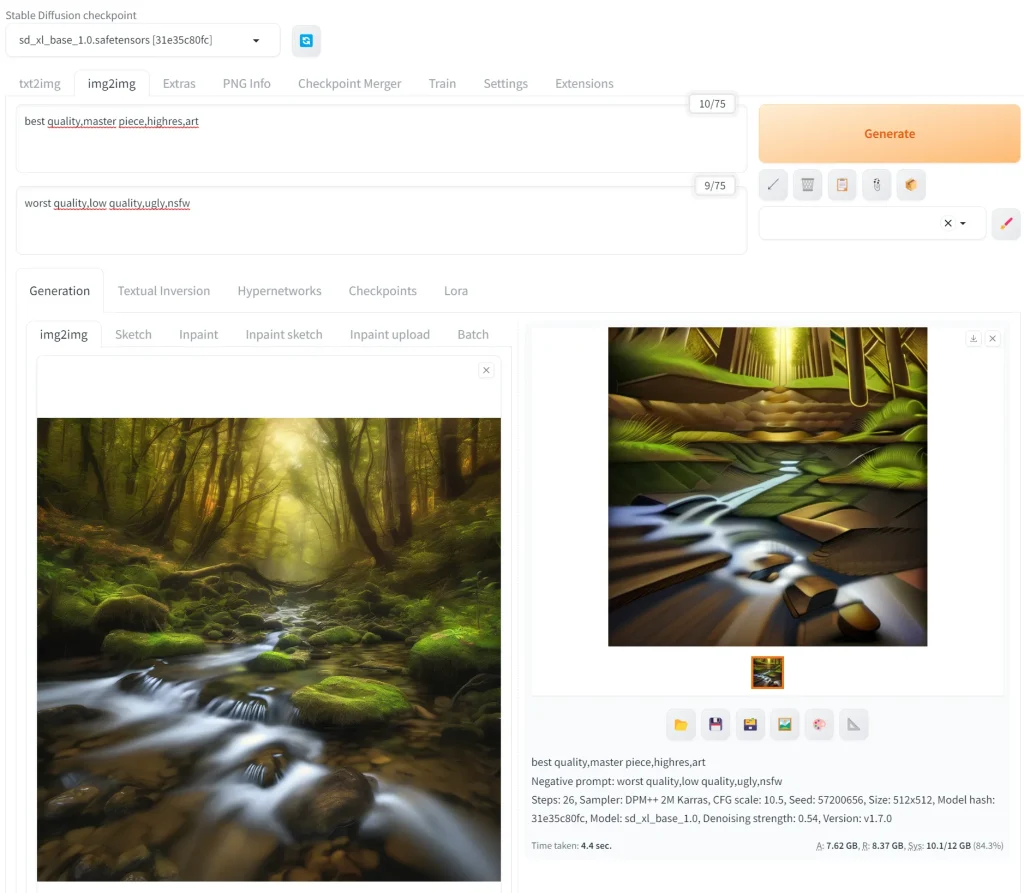
Stable Diffusionの「img2img」では、既存の画像を基にして、新たなビジュアルの画像を生成する機能です。
この機能では、ユーザーが提供する画像に対して、追加のテキストプロンプトや指示を基にして、画像の変換や改変を行います。
たとえば、ユーザーが風景画像と「冬の雪景色に変える」という指示を組み合わせて入力すると、AIはその風景を冬の雪景色に変化させた新しい画像を生成します。
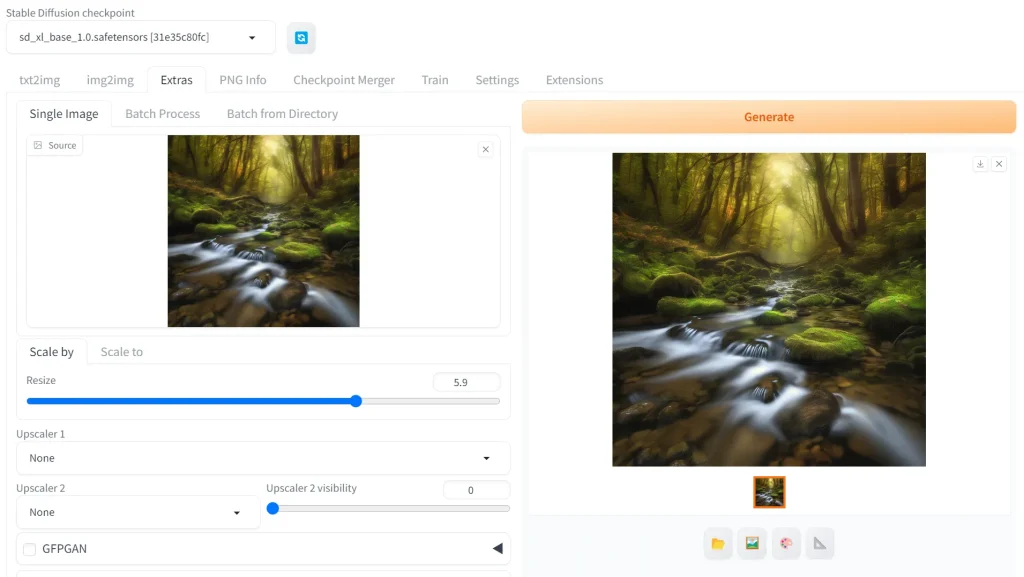
Stable Diffusionの「Extras」では、画像の高画質化が可能です。この機能は、低解像度や品質の低い画像を高品質かつ高解像度の画像に変換できます。
画像の細かい部分に注目し、それらをより際立たせるデティールの強化も可能です。他にも、画像からノイズやグレインを取り除くノイズ除去もできます。
このように、「Extras」機能で既存の画像の品質を大幅に向上させることが可能です。
Stable Diffusionには、その柔軟な機能を活用した多くの拡張機能があります。
例えば、画像を拡張して足りない部分を画像生成によって補間することができます。また、画像の一部分にフォーカスを当てて、その部分を変化させるといった詳細な編集も可能です。他にも、画像の色調を調整したり、画像に特定の感情やテーマを反映させることができます。
これらの拡張機能を通じて、より創造的で個性的な画像を生成することが可能になります。
ここまで読んで、多くの方が気になるのはStable Diffusionの導入方法でしょう。ここからはStable Diffusionの導入方法について具体的に解説していきます。
WindowsやMacなどのOSによって導入方法は異なりますが、最も簡単にできるのはPinokioを利用して導入することです。「手っ取り早く導入したい」という方は該当の項目まで読み飛ばしてください。
まずはWindowsのパソコンのスペックについて確認しましょう。下記のスペックを満たしていることが望ましいです。
ここからは具体的にWindows PCでのインストール手順について解説していきます。
最初に、3.10.6のPythonをインストールする必要があります。異なるバージョンがインストールされていないか予め確認しておきましょう。
Pythonのバージョン確認はコマンドプロンプトを開き、下記のコマンドを実行することで可能です。
1python –version異なるバージョンが導入されていたらアンインストールして、まっさらな状態をつくります。その状態で、Python 3.10.6をインストールします。
Pythonの公式サイトからファイルをダウンロードし、実行して手順に従ってインストールしていきます。
インストールする際、「Add Python 3.10 to PATH」にチェックを入れるようにします。
▶ Python Release Python 3.10.6 | Python.org
Gitもまた、Stable Diffusionを使用するために必要です。Gitの公式サイトからダウンロードしてインストールします。こちらも手順に従ってインストールを進めましょう。
Git Bashを使用して、GitHubからリポジトリをクローンします。
具体的なやり方としては、希望するディレクトリ(フォルダ)を開き、右クリックで「Open Git Bash here」を選択します。そうすると、コマンドプロンプトの画面になるので、下記のコードを実行します。
1git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git実行が完了すると、フォルダの中に「stable-diffusion-webui」というフォルダが作成されます。そのフォルダにある「webui-user.bat」を起動すると、コマンドプロンプトが開き、Stable Diffusionのダウンロードが開始されます。

ダウンロードが完了すると、コマンドプロンプトに「http://127.0.0.1:7860」か「http://localhost:7860」のアドレスが表示されるので、それをブラウザで開きましょう。
Macでの導入はWindowsとは少々異なります。下記の手順に従ってStable Diffusionを導入してみてください。
Finderを開き、アプリケーション>ユーティリティ>ターミナル を開きます。
ターミナルで下記のコマンドを実行してください。
1/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"実行するとHomebrewのインストールが完了します。
インストールが無事に完了しているかを確認するには下記のコマンドを実行しましょう。実行して、Homebrewのバージョンが表示されれば問題ありません。
1brew -v次にStable Diffusionに必要なライブラリなどをインストールする必要があります。ターミナルで下記のコマンドを実行してください。
1brew install cmake protobuf rust python@3.10 git wget次はStable Diffusionのインストールを進めていくのですが、その前にどのフォルダにインストールするのかを指定します。
下記のコマンドを実行してフォルダを指定することが可能です。そのまま実行すると、ユーザーのホームフォルダを指定します。
1CD ~フォルダを指定したら、下記のコマンドでStable Diffusionのインストールを進めていきます。
1git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui完了すると指定したフォルダに「stable-diffusion-webui 」というフォルダが作成されています。
あとは、Windowsと同じように実行していきます。下記のコマンドで実行可能です。
1cd ~/stable-diffusion-webui初回起動時には必要なファイルがダウンロードされるため、時間がかかります。処理が完了したら、続けて下記のコマンドを実行します。
1./webui.sh実行すると、「http://127.0.0.1:7860」か「http://localhost:7860」のアドレスが表示されるので、それをブラウザで開きましょう。
WindowsやMacに環境構築するのは難しいと考えている方もいることでしょう。その場合は、「Pinokio」というツールの活用をおすすめします。
Pinokioは、各パソコンに仮想環境を構築し、その仮想環境内でAIツールを起動できるものです。既存の環境に左右されず、非エンジニアの方でも簡単にAIツールの導入が可能です。
詳細は下記の記事に解説しているので、こちらも併せてご覧ください。

難しくて環境構築ができない方、PCの管理者ではなく環境構築ができない方などはWeb版Stable Diffusionの利用をおすすめします。
下記のどのWebサービスでも、Stable Diffusionと同様にテキストから画像生成が可能です。ただし、細かいパラメータの設定はできないため、本格的に触るためにはローカルに環境構築した方が良いでしょう。
Stable Diffusionの導入が完了したら、次は実際に使ってみましょう。
ここでは、画像生成の手順と生成の際に調整するパラメータについて解説していきます。
まずは画像生成の手順です。ここではあくまで「どのようにして画像を生成するか」に焦点を当てています。Web UIの画面では、「txt2img」のタブでの操作方法になります。
画像のクオリティを上げていくには、プロンプトの調整が必須です。実際に様々なプロンプトを試しながら、イメージに合うプロンプトを見つけてみてください。
プロンプトは、Stable Diffusionで画像を生成する際に最も重要です。プロンプト次第で、生成される画像が大きく異なります。
プロンプトには画像の主題、風景、色彩、スタイルなど、具体的なビジュアル要素を含むことができます。画像に含めたい物体、ポージングなども加えると良いでしょう。
例えば、「静かな森の中の小川」というプロンプトは、森林の中の水の流れを描いた画像を生成するようAIに指示する場合は、下記のようなプロンプトが例として挙げられます。
Stream,Forest,Tranquility
また、下記のようなプロンプトは、どんな画像を生成するときにも使えるおすすめのプロンプトです。
プロンプトが詳細であればあるほど、AIはより正確にユーザーの意図を反映した画像を生成することができます。
ネガティブプロンプトとは、生成される画像に含めたくない要素の指定です。ネガティブプロンプトを指定することで、望まない要素を排除できます。
例えば、「Dark(暗い)」や「horrible(恐ろしい)」といった要素を画像に含めたくない場合は、それらの単語をネガティブプロンプトとして入力します。
また、人体が含まれる画像では、しばしば指やポージングが不自然な状態になる場合があります。下記のプロンプトは、人体が含まれる画像生成には有効です。どのような画像にもおすすめのネガティブプロンプトもまとめましたので、ぜひご活用ください。
ネガティブプロンプトの使用は、より望ましい結果を得るために効果的な手段です。
Stable Diffusionには様々なパラメータで画像生成を制御することができます。
これには、画像の幅や高さといったサイズ、どれくらいの生成プロセスを経て画像にするのかといったステップの数、1回の画像生成で出力する画像の枚数などです。
パラメータに関しては、パソコンのスペックが大きく関係してきます。Stable Diffusionを動かすので精一杯のスペックのパソコンで、無茶なパラメータを設定してしまうと、エラーが起きて処理が止まってしまうこともあります。
各パラメータについては後述しますので、詳細はそちらをご覧ください。
プロンプトの入力やパラメータの調整ができたら、「Generate」ボタンを押して画像生成を実行します。
作業スピードは設定したパラメータやパソコンのスペックに依存します。作業が完了したら、生成された画像が表示されます。
生成された段階で、所定のフォルダにも自動保存されます。改めて保存先を指定して保存することも可能です。
パラメータについては前述のとおりですが、ここではどのようなパラメータがあるのか、そのパラメータの意味や推奨設定について解説していきます。
パラメータについて理解を深め、自身の環境で最適な結果が得られるように工夫してみましょう。
Sampling methodは画像生成時のサンプリング手法。手法によって生成される画像の特徴が異なります。
DDIMやDDPMなどが一般的ですが、最初は気にしなくても問題ありません。「こんな画像がつくりたい!」というイメージが明確になったら、そのイメージに合うサンプリング手法を見つけましょう。
Sampling stepsは生成過程でのステップ数。数が多いほど画像は詳細になりますが、生成する時間も長くなります。
生成する画像の幅をピクセル単位で設定します。大きい値は横幅が広い画像になります。
生成する画像の高さをピクセル単位で設定します。大きい値は縦幅が高い画像になります。
プロンプトと生成される画像との関連性を調整するパラメータ。高い値はよりプロンプトに忠実な画像になります。ただし、プロンプトに左右されるため、上手く調整しないと画像が破綻したものになる可能性があります。
低く設定するとプロンプトへの依存度は下がります。破綻が少なく、AIがよしなに生成する形になりますが、自身のイメージとは異なる画像になりやすいです。
Batch countは一度に生成する画像のセット数。
生成プロセスを通じて何回のバッチ処理が行われるかを指します。たとえば、batch countが2であれば、生成プロセスは2回実行されます。
Batch size各バッチで生成される画像の数。各バッチ処理で生成される画像の数を指します。たとえば、batch sizeが5であれば、一回のバッチ処理で5枚の画像が生成されます。
Batch countと組み合わせて、一連の生成プロセスで合計いくつの画像が生成されるかを決定します。
例えば、Batch countが2でBatch sizeが5なら、2回の生成プロセスで処理されることになり、それぞれ5枚ずつの画像が生成され、合計で10枚となります。
Seedとは、画像生成AIで使用されるランダム性を制御するための数値です。AIが画像を生成する際、多くの場合ランダムな要素が関わりますが、seed値を指定することで、このランダム性を一定に保つことができます。
同じseed値を使用すると、AIは同じランダム要素を使用して、再現性のある結果を生成します。つまり、seed値を変えることで異なる画像が生まれ、同じ値を使用すれば同じ画像が再生成されます。
特定の処理や条件をスクリプトとして実行するためのパラメータ。
Stable Diffusionの基本的な使い方は解説してきましたが、これだけでは完璧に扱うことは難しいでしょう。
自身のイメージどおりの画像を生成するために重要になるのがモデルとLoRAです。ここでは、それぞれについてどのようなものなのか、導入や活用方法について解説していきます。
Stable Diffusionで上手く画像を生成するためには、学習済みのデータセットが含まれている「モデル」の活用が重要です。何も学習されていない状態だと、低品質の画像しか生成されません。
たとえば、美しいアジア人女性の画像データを学習させたモデルを導入すれば、生成結果も学習データを基にした美しいアジア人女性の画像が生成されます。
モデルと同じように「LoRA」も画像生成において重要な要素です。LoRA(Low-Rank Adaptation)とは、モデルの追加データのようなもので、膨大なデータと計算が必要なモデルに対して、少ない時間と量で学習するために用いられる技術です。
モデルとの主な違いとしては、容量が少ないこと、画像生成の際に特定の部分に特化して生成できることと言えます。
例を挙げると、アジア人の美しい女性を学習させたモデル・ショートヘアの女性を学習させたLoRAを組み合わせて、アジア人の美しいショートヘアの女性を生成する…というようなイメージになります。
モデルとLoRAは様々なWebサイトなどで配布されており、代表的なサイトとしては下記が挙げられます。
どちらも無料で様々なモデルやLoRAをダウンロードすることが可能です。生成したい画像のイメージに近いモデルやLoRAを選んでからダウンロードすると良いでしょう。
ダウンロードしたモデルとLoRAはStable Diffusionを導入したフォルダの中に入れて、起動後にモデルを選択します。
モデルの格納先は下記のとおりです。
stable-diffusion-webui > models > Stable-diffusion
LoRAの格納先は下記のとおりです。
stable-diffusion-webui > models > Stable-diffusion > Lora
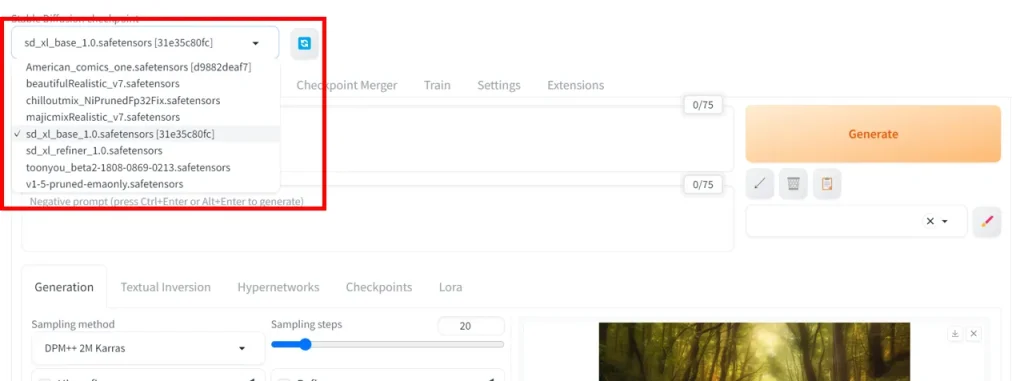
モデルを格納した状態でStable Diffusionを起動すると、プルダウンメニューを押してモデルを選択することができます。すでに起動した状態の場合、右側にある更新ボタンを押すと改めてフォルダの中にあるモデルを読み込んで表示するようになります。
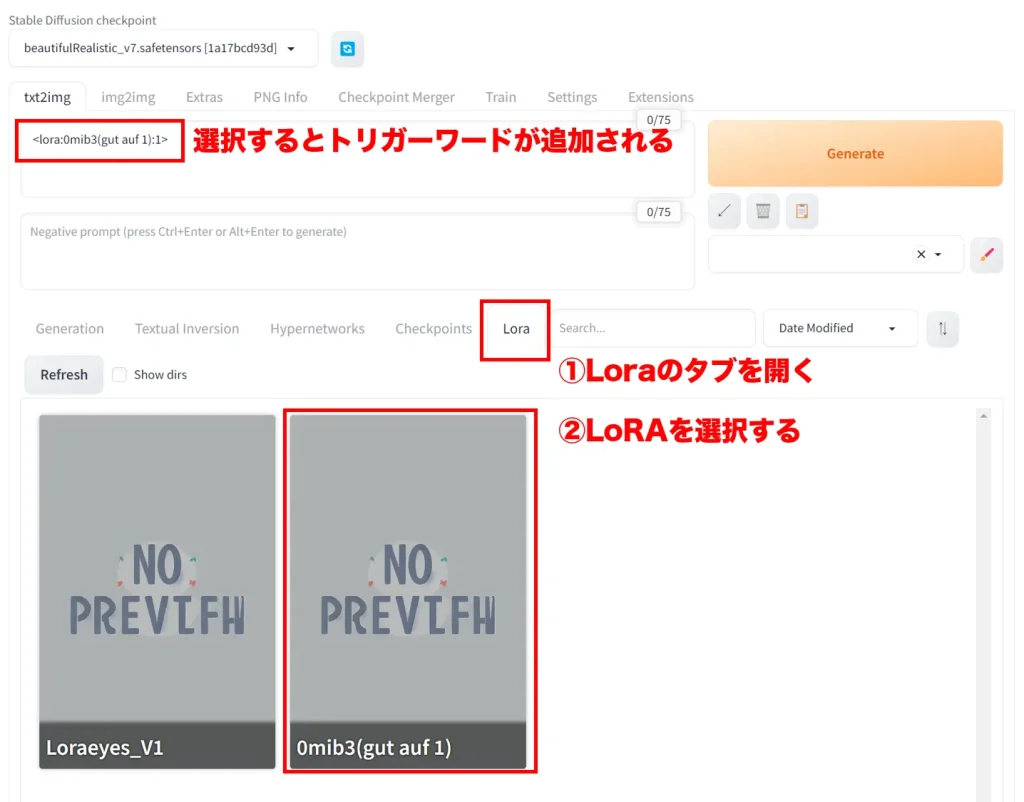
LoRAはタブから選択する形です。「Lora」のタブを開くと導入しているLoRAが選択できます。LoRAをクリックすると、プロンプトにトリガーワードが追加されます。
その状態で「Generate」ボタンを押すと、LoRAが反映された状態で画像生成が可能です。
画像生成を簡単に行えるStable Diffusionですが、使用する際に必ず押さえておくべき注意点があります。便利なツールですが、間違った使い方をすると多くの方に迷惑をかける、法律を違反するなどの恐れがあります。
ここで解説することをよく理解し、参考情報まで読むことを推奨します。
Stable Diffusionを商用利用する際は、特に注意が必要です。前提として、Stable Diffusion自体を商用利用することは問題ありません。問題なのは生成した画像です。
モデルやLoRAは著作権を無視して学習されていることもあります。どのようなデータを基に学習しているかを確認することが大切です。
そのようなモデル・LoRAを活用して生成した画像は、場合によっては著作権、知的財産権を侵害する可能性もあります。
適切な使用のために、政府が発表している方針を確認しておくと良いでしょう。
参考: 文化庁|「知的財産推進計画2023」等の政府方針等(著作権関係抜粋)
参考: 総務省|令和5年版 情報通信白書|生成AIを巡る議論
Stable Diffusionを使用する際は、倫理を重んじ、社会的な影響を考慮することが重要です。人物の肖像権やプライバシーを尊重し、不適切または攻撃的な内容の生成を避けましょう。
画像生成ではありませんが、実際に倫理観を逸脱し、社会的に悪影響となった事例をご紹介します。
2023年11月頃、岸田総理のフェイク動画が大きな社会問題になりました。その動画では、岸田総理の音声を学習させたAIで声を岸田総理の声にして、岸田総理が言わないであろうことを発言させる動画になっています。
動画制作者は悪ふざけのつもりでも、大きな社会問題になってしまいます。
参考:相次ぐ「AI偽動画」あなたはディープフェイクを見抜けますか? | NHK | フェイク対策
Stable Diffusionを使用する際も、自身が生成する画像を公開することでどのような影響があるのか、公開しても問題ないと言える根拠やデータを揃えた上で公開するなど、使い方には細心の注意を払いましょう。
ここでは、Stable Diffusionとは何か、仕組みや機能、導入方法から使い方まで詳しく解説してきました。Stable Diffusionをマスターするには、モデルやLoRAの活用も必須ですし、細かいパラメータの調整方法なども身に着けていく必要があります。
画像生成を上手くなるためには、試行錯誤して繰り返し生成していく他ありません。進化の早いAI業界のため、日々の情報収集も大切です。
ぜひStable Diffusionを使いこなして自身の活動を加速させていきましょう。
Team HESHINでは様々なAIツールに積極的に触れ、クリエイティブの制作に活用しています。Stable Diffusionも同様に様々な実験を重ねて、思い通りの画像を生成できるようになりました。
Stable Diffusionの使い方をお伝えすることも可能ですので、使い方に悩む個人の方や自社サービスなどに活かしたい企業の方など、お気軽にお問い合わせください。
その他、AIを活用したサービスについては、下記のページもご覧ください。






