生成AIで漫画ができる!? おすすめのツールと具体的なやり方を解説
ryo
HENSHIN Lab


AIで声を変換できるRVCでは、モデルの品質によって想像どおりの声になれるかが左右されます。そのため、モデル作りは非常に大切な工程と言えます。
ここでは、RVCのモデルの作り方をご紹介します。学習データの用意する方法や音声データの加工方法、どのように学習させるかを実際の画面を用いて詳しく解説しているので、ぜひ参考にしてみてください。
また、TEAM HENSHINではRVC制作代行も承っています。
設定に行き詰まったり、動画配信等で理想の声を使いたい方は
お気軽にご相談ください!

RVC(Retrieval-based-Voice-Conversion)は、AI技術を利用した革新的な声変換ツールです。リアルタイムでの声の変換を可能にし、さまざまな用途で活用されています。
RVCでは、音声データをAIに学習させることで、異なる声質への変換を実現します。次世代のボイスチェンジャーとして注目されています。
RVCの用途や導入方法については、下記の記事をご覧ください。

ここからはRVCのモデルの作り方について解説していきます。モデルの作り方は具体的には下記の流れになります。
各項目について詳しく解説していきます。
まずはモデル制作のために必要な音声データを集める作業です。
自分の音声を読み込ませるような場合は、声の録音が必要です。インターネット上から音声データを探して学習させることも可能です。
なお、学習のために必要なデータは10〜50分になります。モデルのクオリティに関わるので、少なすぎないように気をつけましょう。また、長すぎても品質が落ちる場合もあるので注意が必要です。
ここでは収集のコツについてご紹介していきます。
良質な学習データにするためには、適切な録音環境の設定が重要です。
まず、静かな部屋を選び、外部の騒音やエコーを最小限に抑えます。高品質なマイクロフォンの使用と、マイクと話者の距離を適切に保つことも必要です。
さらに、一貫した音量とクリアな発音で録音を行い、音声データの一貫性を保つことが大切です。
これらの条件を整えることで、RVCの学習効率と変換品質を高めることができます。
ネットから音声データを収集する際は、再現したい声が安定していることが重要です。
特に感情の起伏が声に強く反映されているデータは避け、均一なトーンのデータを選ぶと良いでしょう。たとえば、地声と裏声が混在するような音声データがこれに当てはまります。
BGMが含まれる音声データでも問題ありません。音声データを加工する工程でBGMとの分離が必要になります。
声だけのクリアなデータを集めると、加工の工程が割愛できます。
また、音声データの使用には著作権関係の注意が必要です。特に商用利用の場合は「商用利用可」と明記されたものを選びましょう。
これはRVCだけでなく、他の生成AIでも共通の注意点です。
学習させるデータは下記のポイントを意識して作りましょう。
また、加工方法については下記のやり方で行うと良いでしょう。
RVC WebUIでは「UVR5(Ultimate Vocal Remover v5)」というボーカルリムーバー機能が備わっており、音声とBGMが混合した音声データをそれぞれ分離することが可能です。
やり方としては下記のとおりです。
RVC WebUIの「伴奏ボーカル分離&残響除去&エコー除去」を開く

「処理するオーディオファイルのフォルダパスを入力してください」に分離したい音声データのパスを入力します。もしくはその下の欄にファイルをドラッグ&ドロップします。
「マスターの出力音声フォルダーを指定する」「マスター以外の出力音声フォルダーを指定する」は出力するファイルの保存先を選択します。
設定が完了したら「変換」で処理を開始します。
上記で分離が完成します。
前述のとおり、この機能はUVR5のもので、RVC WevUIに付属する機能はおまけのようなものです。より精密に行いたい場合は、UVR5の本体を使ってみましょう。
音声加工ソフトで音声をクリアにしたり、空白を除去する方法について解説します。ここでは、広く使用されている無料の音声編集ソフトウェア「Audacity」を例に挙げて説明します。
まず、Audacityの公式HPから最新版をダウンロードしてインストールしましょう。作業のやり方について、詳細は参考ページをご紹介しますのでそちらをご覧ください。
音声をクリアにする”ノイズリダクション”について、下記を参考にし作業してみましょう。
【簡単!】無料ソフトAudacityでノイズ除去をする方法 | Vook(ヴック)
不要部分を削除する空白の除去について、下記を参考に作業してみましょう。
【Audacity】無音検出で余分な間をカットする方法!トークのテンポアップにも使える – AKETAMA OFFICIAL BLOG
編集が完了したら、「ファイル」メニューから「エクスポート」を選択して、wav形式で音声ファイルを保存します。
音声データの収集と加工が完了したら、RVCに学習させます。
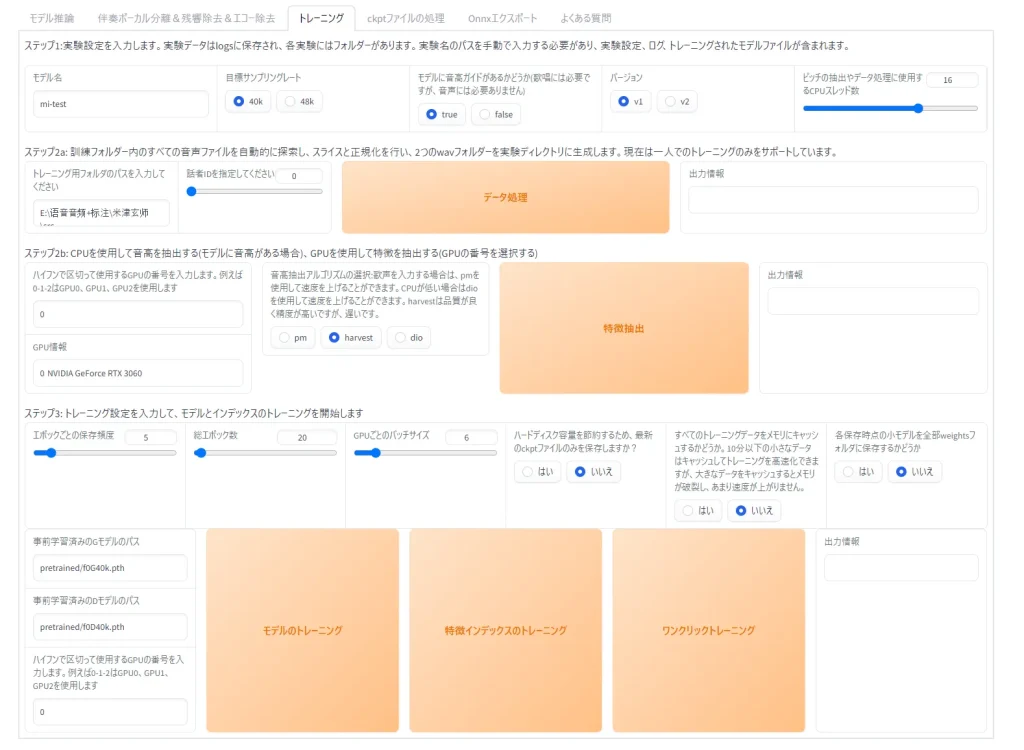
RVCの「トレーニング」タブを開くと上記の画面になります。
モデル名の設定では、モデルにわかりやすい名前を付けます。
目標サンプリングレートでは、学習データに合わせて適切なサンプリングレートを選択します。一般的には40kHzが適切です。
「モデルに高音ガイドが…」の項目では「true」に設定しておきましょう。
バージョンは「v2」を選択します。
CPUスレッド数は処理速度に関する設定です。
タスクマネージャーを開き、「パフォーマンス」タブを選択します。「CPU」セクションを選ぶと、右下に「論理プロセッサー」という項目があります。その数値が、PCの論理プロセッサ数です。
こちらの数値の約70%を設定すると良いでしょう。
ステップ2の音声データのフォルダパスでは、加工した音声データのフォルダを指定します。スペースが含まれていないフォルダパスにしましょう。また、日本語が入ると上手く読み込めないことがあるため注意してください。
音高抽出アルゴリズムの選択では「harvest」を選択します。
ステップ3のエポックごとの保存頻度はそのままの設定で問題ありません。
総エポック数は、値を大きくすると学習にかける時間も増えます。基本的には30前後で設定しておけば問題ありません。音声データが少ない場合は低めに設定しておき、十分なデータ量がある場合は長めに設定しておきましょう。
GPUごとのバッチサイズは、GPUの力をどれくらい使用して処理するか決められます。GPUのVRAM容量に応じてバッチサイズを調整しましょう。基本的にはそのままで問題ありません。GPUの性能が高いPCだと、少し上げてみても良いでしょう。
設定が完了したら「ワンクリックトレーニング」をクリックして学習を開始します。
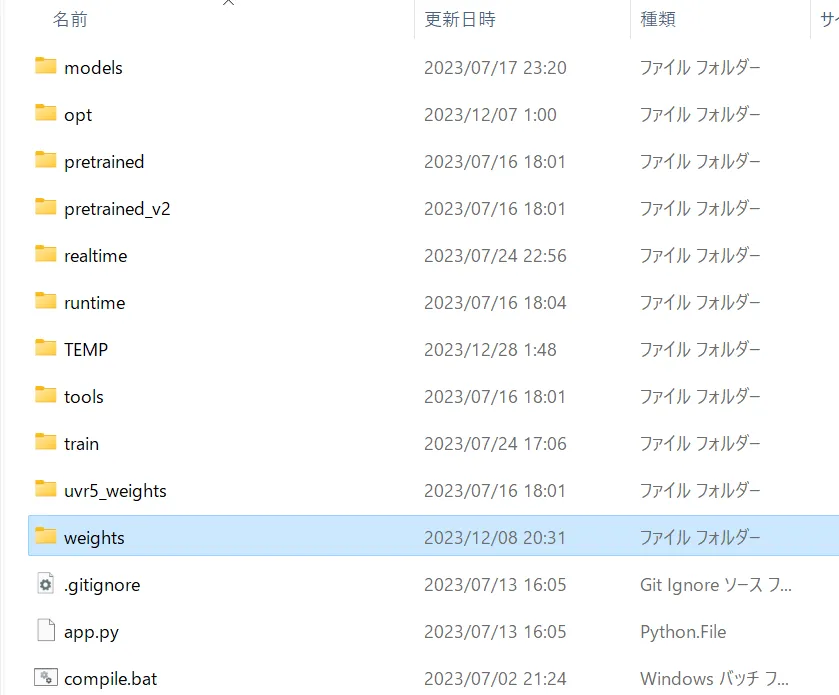
学習が終わると、weightフォルダにpthファイルが作成されます。そちらが学習済みのModelとなります。
学習済みのモデルをどのように使用するかは下記の記事の「RVCの使い方」の項目で解説しています。
ここからの流れは下記の記事をご覧ください。
ネットでは事前に学習させたモデルが配布されています。下記のサイトでは有料のモデルや無料のモデルなどが配布されています。
モデルの作成が手間だと感じる方は、下記のサイトを利用してみるのも良いでしょう。
▶ つくよみちゃん公式RVCモデル/つくよみちゃんUTAURVC | つくよみちゃん公式サイト
▶ RVCに関する人気の同人グッズ144点を通販できる! – BOOTH
※ モデルの利用範囲については、各ページの規約をご覧ください。
RVCで使えるモデルの作り方について、学習データの収集や加工、学習の方法について解説してきました。
高品質なモデルにするためには、学習元となるデータの品質が非常に大切になります。しっかりと時間をかけて良いデータを取れるようにしましょう。
「こんな声にしたい!」というイメージはあるものの、自分で作業が難しいという方はTeam HENSHINで作業代行も承っております。作業のご依頼はお問い合わせページよりご連絡ください。
RVCを活用して、動画のナレーションやVtuberの活動など、ご自身の活動に活かしてみてください。







